リオーダーバッファは、アウトオブオーダー実行をするプロセッサにおいて、その投機的な状態を保存するバッファです。 リオーダーバッファのサイズは、命令ウィンドウ(実行順序を並べ替える範囲)の大きさの上限を決めます。
命令ウィンドウに含まれる、依存関係のない複数の命令列は並列に実行できますが、命令ウィンドウに含まれない場合は並列に実行できません。 そこで、依存関係のない複数の命令列の間の命令数を徐々に増やしていくと、並列に実行できる命令列から並列に実行できない命令列に変わっていきます。 これを利用して、リオーダーバッファのサイズを測ってみます。
使用するアセンブリプログラム
.text
.intel_syntax noprefix
.globl main
main:
.cfi_startproc
mov eax, 10000000
.p2align 4, 0x90
L:
xorpd xmm0, xmm0
addsd xmm0, xmm0
addsd xmm0, xmm0
(略:addsdが30個)
addsd xmm0, xmm0
addsd xmm0, xmm0
xor edx, edx
xor edx, edx
(略:xorがN個)
xor edx, edx
xor edx, edx
dec eax
jne L
.cfi_endproc
addsd命令を直列につなげることで、なかなか実行が終わらない命令を作り出します。
xor命令は、次のループに含まれるaddsd命令列との距離を離すために使用する、ただの無意味な命令です。
測定結果
HaswellアーキテクチャのCPUで測定した結果が以下の図になります。横軸がxor命令の数、縦軸が実行にかかったサイクル数です。
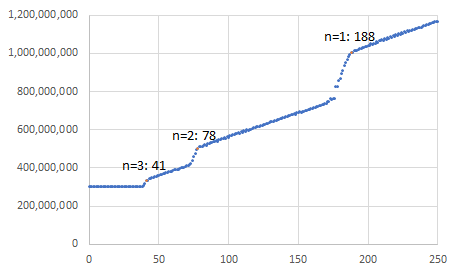
Haswellアーキテクチャのリオーダーバッファのサイズは192なので、xor命令が188個以上の場合、直列に並んだ最後のaddsd命令が終わるまで次のループのaddsd命令を命令ウィンドウに取り込めません。
測定結果は、これと整合します。
また、xor命令が78個以上の場合、直列に並んだ最後のaddsd命令が終わるまで次の次のループのaddsd命令を命令ウィンドウに取り込めません。
これも測定結果と整合しています。
さらに、xor命令が41個以上の場合、直列に並んだ最後のaddsd命令が終わるまで3つ次のループのaddsd命令を命令ウィンドウに取り込めません。
これも測定結果と整合しています。
Haswellアーキテクチャではaddsd命令は3並列でしか実行できないので、それ以上xor命令を減らしても実行にかかる時間はほぼ一定です。
なお、n=1, 2, 3以外の部分で少しずつ性能が下がるのは、無意味な命令がフェッチ幅を浪費していることによるものです。 実際、その部分での傾きは0.25であり、Haswellアーキテクチャのフェッチ幅4 instructions/cycleと整合します。
Apple M1 でもやってみた
同様のプログラムをARMでも作成し、Apple M1で動かしてみました。
長いレイテンシを作るための命令は、50個配置しました。
横軸は無意味な命令として使ったmov x9, #0命令の数、縦軸は実行にかかった秒数です。
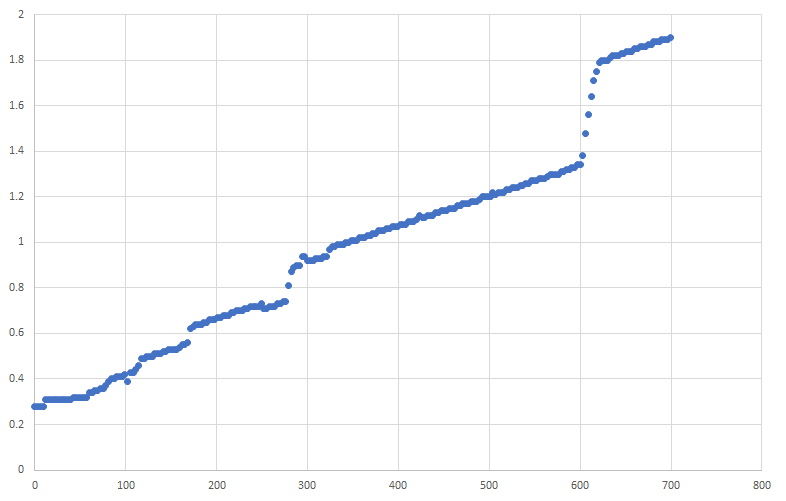
無意味な命令の数が622個のところで傾きが変わっていることから、Apple M1(の高性能コア)のリオーダーバッファのサイズは626であるとわかります。
これは、他の方法(非常に長いレイテンシを持つメモリアクセス命令を用いた方法)により測定された結果(Apple's Humongous CPU Microarchitecture - Apple Announces The Apple Silicon M1: Ditching x86 - What to Expect, Based on A14)とも一致しています。